
티스토리 뷰
✔️ Text Splitter란?
RAG(Retrieval-Augmented Generation)에서 Text Splitter(텍스트 분할기)는 긴 문서를 작은 청크로 나누어 효율적인 검색과 문서 임베딩을 가능하게 하는 핵심 도구이다.
Text Splitter의 주요 역할
- 긴 문서를 작은 단위로 분할
- LLM (대형 언어 모델)은 입력 길이에 제한이 있음. 처리해야하는 문서가 많은 데이터를 포함하고 있다면 입력 길이 제한에 걸릴 것임. 따라서 문서를 적절할 크기로 나누어 처리해야 함.
- 효율적인 검색 최적화 : Retrieval
- 문서를 청크 단위로 저장하고 검색하면, LLM이 질문에 맞는 관련 정보를 빠르게 찾을 수 있음.
- 청크 단위 :
- 문서를 청크 단위로 저장하고 검색하면, LLM이 질문에 맞는 관련 정보를 빠르게 찾을 수 있음.
- 연관성 높은 문서 조각을 제공
- 문서가 너무 크면 의미가 있는 부분을 추출하기 어려움. 적절한 크기로 나누면 검색 성능이 향상된다.
- 문서의 일관성 유지
- 문장을 임의로 끊는 것이 아니라 문맥을 고려하여 적절한 단위로 분할해야 한다.
✔️ CharacterTextSplitter
특정 구분자(separator) (예: 개행 문자 \\n,단락)를 기준으로 문서를 나누는 방법이다.
- 단순히 개행 문자 (\\n\\n, \\n) 또는 공백(" ")을 기준으로 문서를 나누는데, 문맥을 손실 시킬 가능성이 있다. (특정 구분자 기준으로 나눔)
- 설정된 chunk_size(청크 크기)와 chunk_overlap(청크 간 중복 크기)를 기반으로 분할 된다.
- 뉴스, 블로그, 책과 같이 구조적으로 문장이 구분된 데이터를 분할할 때 유용하다.
1. 주요 매개변수
- chunk_size: 청크 최대 크기
- chunk_overlap: 청크 간 중복 부분
- ex. "민수는 학교에 간다." -- chunk_size :2 and chunk_overlap : 1
- --> "민수는 학교에", "학교에 간다." : 학교에 중복
- separator: 분할 기준 문자
2. 분할 전략
- 의미 단위: 마침표(.) - 문장 보존
- 구조 단위: 줄바꿈(\n) - 문단 보존
- 단어 단위: 공백( ) - 세밀한 분할
3. chunk_overlap의 중요성
- 청크 간 맥락 보존하여 연결성을 유지할 수 있다.
- 문장이 잘리는 문제를 해결하여, 정보 손실을 방지할 수 있다.
✔️RecursiveCharacterTextSplitter
RecursiveCharacterTextSplitter는 문서를 분할할 때 설정된 문자 목록을 순서대로 사용하여 가장 적절한 크기로 나누는 방식이다.
"\n\n"(문단 단위)로 분할 시도 -> "\n"(줄 단위) -> " " (단어 단위) -> "" (문자 단위) 순으로 진행된다.
RecursiveCharacterTextSplitter는 문단, 문장, 단어 순으로 분할을 시도한다. 이는 문장을 끊기지 않도록 가능한 한 문맥을 유지한 상태로 텍스트를 나눌 수 있다.
문맥 유지를 위한 설정
chunk_overlap은 chunk_size의 20~30% 정도로 설정
separators를 활용해 의미 단위로 끊기도록 조정 (["\n\n", ".", ",", "!", "?"])
❓ 언제 사용하는가
연구 논문, 기술 문서처럼 구조가 명확하지 않은 긴 텍스트를 효과적으로 나눌 때 유용하다.
계층적 분할로 의미 단위를 최대한 보존하면서 적절한 크기의 청크를 만들 수 있다.
1. Recursize와 Character의 차이점
Recursize는 여러 구분자를 우선순위에 따라 시도한다.
Character은 하나의 구분자만을 사용한다.
2. separators 우선순위
separators=["\n\n", "\n", ".", " "]
# 1순위: 문단 구분 (\n\n)
# 2순위: 줄바꿈 (\n)
# 3순위: 문장 구분 (.)
# 4순위: 단어 구분 ( )# 일반 문서용
RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["\n\n", "\n", ".", " "]
)✔️TokenTextSplitter
TokenTextSplitter은 토큰 개수를 기준으로 문서를 분할하는 방식
LLM은 단어가 아닌 토큰(Token) 단위로 입력을 처리한다.
따라서 모델(LLM의 모델)의 입력 제한을 초과하지 않도록 분할하는 것이 중요하다.
OpenAI의 GPT 계열 모델처럼 토큰 단위로 입력을 받는 모델을 사용할 때는 TokenTextSplitter가 유용하다.
TokenTextSplitter을 활용하면 입력 토큰 제한을 초과하지 않도록 관리가 가능하다.
TokenTextSplitter은 실제 LLM이 인식하는 토큰 개수로 분할하기 때문에 LLM의 실제 토큰 처리 방식과 더 잘 맞는다.
특징
토큰 단위 분할 : 문자가 아닌 토큰 개수로 청크 크기를 결정한다.
정확한 제어 : LLM 토큰 제한을 정확히 준수한다.
tiktoken 활용 : OpenAI 모델과 동일한 토큰화 방식이다.
다른 Splitter과 차이점
토큰 기반
# 문자 기반 (RecursiveCharacterTextSplitter)
chunk_size=800 # 문자 개수
# 토큰 기반 (TokenTextSplitter)
chunk_size=200 # 토큰 개수
인코딩 방식
- cl100k_base: GPT-4, GPT-3.5-turbo (현재 표준)
- p50k_base: GPT-3 (legacy)
- 한국어 처리 성능이 우수
권장하는 설정 방법
TokenTextSplitter.from_tiktoken_encoder(
chunk_size=500, # 임베딩용
chunk_overlap=50, # 10% 중복
encoding_name="cl100k_base"
)
내부적으로 tiktoken 라이브러리를 사용해서 토큰 개수를 세고 분할한다.
⭐ tiktoken이란?
OpenAI에서 개발한 토큰화(Tokenization) 라이브러리이다.
GPT-3, GPT-4 등의 모델이 사용하는 토큰화 방식을 제공한다.
ex. "ChatGPT is amazing!" -- 토큰화 --> [2023, 345, 8723, 12] 형태의 토큰으로 변환
tiktoken활용 : OpenAI 모델과 동일한 토큰화 방식을 사용한다.
참고로 tictoken은 OpenAi에 포함되어 있어서 개별적으로 설치해줄 필요가 없다.
장단점
❓ 그럼 언제 사용하는가
✔️Hugging Face Tokenizer
Hugging Face란?
HuggingFace는 AI 모델 개발, 공유, 배포를 위한 강력한 오픈소스 플랫폼이다.
AI모델의 'GitHub"같은 공간이라고 말할 수 있다.
자연어 처리(NLP), 컴퓨터 비전(CV), 음성 인식(Speech) 등의 다양한 AI 모델을 쉽게 사용할 수 있도록 지원합니다.
Hugging Face Tokenizer란?
Hugging Face의 Tokenizer는 NLP 모델에서 텍스트를 처리할 때 토큰화(Tokenization) 작업을 수행하는 도구입니다.
텍스트를 단어, 서브워드, 문장 등 다양한 단위로 변환하며, 사전 학습된 토큰화 방식을 활용하여 언어 모델의 입력 형식에 맞게 변환합니다.
주요 특징
- 사전 학습된 모델 사용 가능 : BERT, GPT, T5 등 다양한 모델 지원
- Fast Tokenizer 제공 : Rust 기반의 빠른 토큰화(FastTokenizer) 지원
- 다양한 토큰화 방식 지원 : WordPiece, Byte Pair Encoding(BPE), SentencePiece 등
- 특수 토큰 처리 가능 : [CLS], [SEP], [MASK], <pad> 등의 토큰을 자동으로 추가
- 병렬 토큰화 지원 : 다중 문장 처리 속도 향상
주요 기능
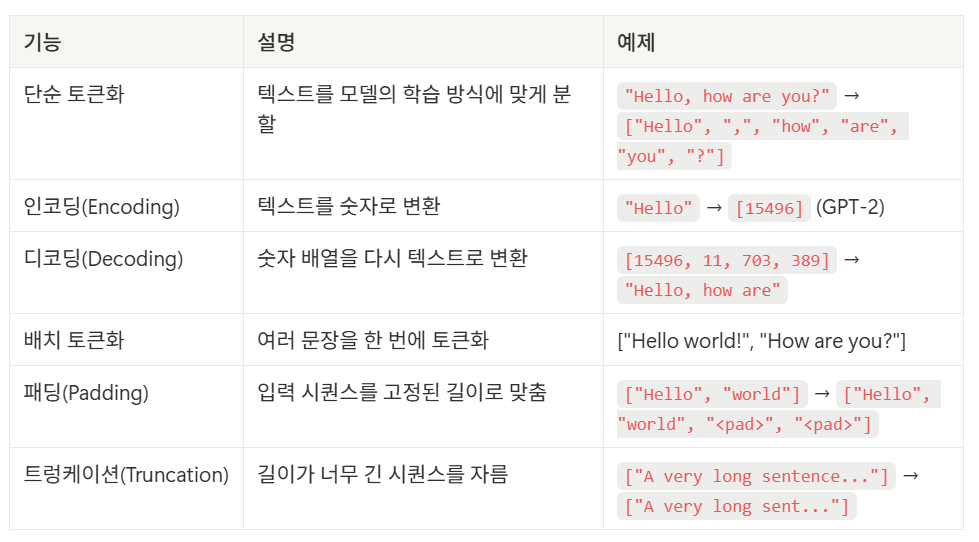
- Hugging Face Tokenizer 중 GPT2TokenizerFast를 사용
- Hugging Face의 GPT2TokenizerFast는 사전 학습된 토큰화 방식을 사용하여 입력 텍스트를 토큰 단위로 변환하는 역할을 한다.
- 이를 통해 토큰 개수를 기반으로 텍스트를 분할하거나, 모델 입력에 맞게 처리하는 데 사용된다.
- GPT-2 모델의 입력 한계를 고려하여 적절한 청크 크기 설정
- chunk_size=100, chunk_overlap=20로 토큰 기반 분할
- 너무 긴 입력을 방지하고, LLM이 이해하기 좋은 단위로 조정
'인공지능' 카테고리의 다른 글
| [LangChain] RAG 단계 중 Embedding 알아보기 (4) | 2025.06.12 |
|---|---|
| [AI학습] 정밀도, 재현율, mAP 수치 확인하기 _ YOLOv8 (0) | 2025.02.23 |
| [YOLOv8] helmet detection project4 _ 최종 (0) | 2024.06.09 |
| [Colab] 꿀팁 및 주의사항 (1) | 2024.06.07 |
| [YOLOv8] colab을 통한 AI학습, helmet detection project2 (0) | 2024.06.06 |
- Total
- Today
- Yesterday
- 다인승
- JAVA오류해결
- database연결
- 사람검출
- 터틀그래픽 명령어
- 다인승탑승
- konlpy
- UnsupportedClassVersionError
- Kkma
- 사람수세기
- tweepy
- randint
- SPRING오류해결
- 파이썬
- 터틀그래픽
- gradleload오류
- 10828번
- python공부
- Turtle Graphic
- yolov8
- 백준
- 에러발생
- YOLO
- streamlistener
- 문제풀이
- baekjoon
- 터틀그래픽예제
- springboot
- randrange
- 오븐시계
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |