
티스토리 뷰
✔️ Embedding이란?
임베딩은 기계가 이해할 수 있는 수치적 형태인 백터로 변환하는 과정이다.
임베딩은 RAG(Retrieval-Augmented Generation) 시스템의 세 번째 단계이다.
Document Load ➡️ Text Splitter ➡️ Embedding 이다.
문서 분할 단계에서 생성된 문서 단위를 기계가 이해할 수 있는 수치적 형태(백터)로 변환하는 과정이다.
임베딩 과정은 RAG 시스템의 핵심 요소 중 하나이다. 문서의 의미를 벡터(숫자의 배열) 형태로 표현함으로써 사용자가 입력한 질문(Query)에 대해 DB에 저장된 문서 조각(청크, Chunk)을 검색하고 유사도를 계산하는 데 활용된다.
주요 활용 사례
의미 검색 (Semantic Search)
- 백터 표현을 활용하여 의미적으로 유사한 텍스트를 검색하는 방식
- 사용자가 입력한 쿼리에 대해 가장 관련성이 높은 문서나 정보를 효과적으로 찾아낼 수 있음
문서 분류 (Document Classification)
- 임베딩된 텍스트 벡터를 사용하여 문서를 특정 카테고리나 주제로 분류하는 작업
- 뉴스 분류, 고객 피드백 분석 등 다양한 NLP 응용 가능 (자연어 처리)
텍스트 유사도 계산 (Text Similarity Calculation)
- 두 개의 텍스트 벡터 사이의 거리를 계산하여 유사도를 평가
- 코사인 유사도(Cosine Similarity)를 활용하여 두 문장이 얼마나 비슷한지 수치화할 수 있음
- 아래 사진을 보면 v2와 v1이 있는데, 그 거리를 계산하지 않고 cos 각도를 계산하는 거다. 각이 작을수록 유사도가 높다고 할 수 있다.

임베딩 모델 제공자
- OpenAI
GPT 계열 모델을 기반으로 텍스트 임베딩을 생성할 수 있는 API 제공
대표적인 임베딩 모델 : text-embedding-3-small, text-embedding-ada-002
- Hugging Face
Transformers 라이브러리를 통해 다양한 오픈소스 임베딩 모델 제공
대표적인 모델 : sentence-transformers 계열
Gemini, Gemma 등의 언어 모델에 적용되는 임베딩 모델 제공
Google의 Vertex AI에서도 다양한 임베딩 모델을 지원한다.
임베딩 메소드
- embed_documents
문서 객체의 집합을 입력으로 받아 각 문서를 벡터 공간의 임베딩 하는 메소드이다.
대량의 텍스트 데이터를 배치(batch) 단위로 처리할 때 유용하다.
- embed_query
단일 텍스트 쿼리를 입력으로 받아, 이를 벡터 공간의 임베딩 하는 메소드
사용자의 검색 쿼리를 벡터화하여 문서 집합 내에서 가장 관련성이 높은 내용을 찾아내는 데 활용한다.
✔️ Embedding 종류 디테일 설명
OpenAIEmbeddings VS HuggingFaceEmbeddings
✔️ OpenAIEmbeddings이란?
OpenAI에서 제공하는 텍스트 임베딩 모델을 활용하여 문장이나 단락을 벡터 형태로 변환하는 기능을 수행한다.
의미적으로 유사한 텍스트를 찾거나, 검색 시스템, 문서 분류 등에 활용할 수 있다.
주요 기능
- 텍스트를 벡터(숫자의 배열)로 변환
자연어 데이터를 머신러닝 모델이 이해할 수 있는 형태로 변환한다.
텍스트 간의 의미적 유사도를 비교하는 데 활용한다.
- 의미 검색 (Semantic Search)
사용자의 쿼리와 데이터베이스 내 문서 간 유사도를 계산하여 관련성이 높은 결과를 찾는다.
- 문서 분류 및 클러스터링
벡터화된 텍스트 데이터를 기반으로 특정 카테고리로 분류하거나 그룹화를 할 수 있다.
❓클러스터링이란
클러스터링(clustering)은 벡터화된(임베딩) 텍스트 데이터를 기반으로 비슷한 특성을 가진 문서나 데이터를 자동으로 그룹(cluster)으로 묶는 비지도 학습 방법이다. 임베딩 벡터 공간에서 서로 가까운 위치에 있을 때 비슷하다고 한다.
- 유사도 계산
코사인 유사도(Cos) 등을 사용하여 두 문장 또는 문서간의 의미적 유사성을 평가한다.
주요 함수
- embed_query(text: str) -> List[float]
단일 쿼리(문장)를 벡터로 변환한다.
ex. 검색 시스템에서 사용자 쿼리를 벡터로 변환 -> 문서와 비교
- embed_documents(texts: List[str]) -> List[List[float]]
여러 개의 문서를 벡터로 변환한다.
ex. 대량의 문서를 미리 벡터화하여 db에 저장한다. -> 검색 시 비교한다.
- dimensions (임베딩 차원 설정)
기본적으로 모델에 따라 임베딩 차원이 정해져 있지만, 일부 모델은 dimensions 매개변수를 통해 설정 가능하다.
ex. text-embedding-3m-small 모델의 기본 차원은 1536이다. 하지만 특정 크기로 조정할 수 있다.
❓여기서 기본 차원이 1536이라는 건
기본 차원 == 임베딩 벡터의 길 (벡터 배열의 숫자 개수)
해당 모델이 하나의 텍스트(문장)를 입력받아 1536개의 실수(float)로 이루어진 벡터로 변환한다는 뜻이다.
벡터의 차원이 높을수록 더 미세하고 다양한 의미의 정보를 담을 수 있다. 하지만, 계산량과 저장공간도 커지기 때문에 주의할 필요가 있다.
✔️ HuggingFaceEmbeddings이란?
HuggingFaceEmbeddings는 Hugging Face에서 제공하는 사전 학습된 언어 모델을 사용하여 텍스트를 벡터(Embedding)로 변환하는 도구입니다. 주로 자연어 검색, 문서 유사도 분석, 의미 기반 검색 등의 작업에 활용됩니다.
주요 기능 및 역할
- 텍스트를 벡터로 변환 : 기계가 이해할 수 있는 수치적 표현 생성
- 문서 검색 및 유사도 분석 : 벡터 간 거리를 계산하여 의미적 유사성 판단
- Hugging Face 모델 사용 : sentence-transformers 기반 다양한 모델 지원
- 로컬 또는 GPU에서 실행 가능 : OpenAI API 없이도 실행 가능
다양한 모델 비교
- all-MiniLM-L6-v2: 소형, 빠른 속도 (384차원)
- all-mpnet-base-v2: 중형, 균형잡힌 성능 (768차원)
- paraphrase-multilingual-MiniLM-L12-v2: 다국어 지원
한국어 처리 분석
- 한국어 텍스트별 벡터 특성
- 벡터 크기, 평균, 표준편차 분석
주요 함수
- embed_documents(texts:List[str]), embed_query(text: str)
- from_pretrained(model_name: str)
특정 사전 학습된 모델을 로드한다.
- batch_encode_plus(texts: List[str])
텍스트를 한 번에 여러 개 변환하여 배치 처리한다.
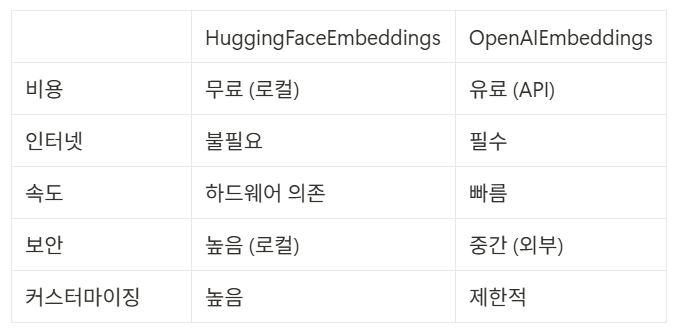
비교
'인공지능' 카테고리의 다른 글
| [LangChain] RAG 단계 - Text Splitter 알아보기 (0) | 2025.06.12 |
|---|---|
| [AI학습] 정밀도, 재현율, mAP 수치 확인하기 _ YOLOv8 (0) | 2025.02.23 |
| [YOLOv8] helmet detection project4 _ 최종 (0) | 2024.06.09 |
| [Colab] 꿀팁 및 주의사항 (1) | 2024.06.07 |
| [YOLOv8] colab을 통한 AI학습, helmet detection project2 (0) | 2024.06.06 |
- Total
- Today
- Yesterday
- 파이썬
- 터틀그래픽
- Kkma
- konlpy
- 에러발생
- 터틀그래픽예제
- SPRING오류해결
- 터틀그래픽 명령어
- UnsupportedClassVersionError
- YOLO
- 10828번
- streamlistener
- gradleload오류
- 백준
- randrange
- tweepy
- randint
- baekjoon
- 사람검출
- 다인승탑승
- 다인승
- 사람수세기
- 오븐시계
- yolov8
- 문제풀이
- springboot
- python공부
- JAVA오류해결
- Turtle Graphic
- database연결
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |